tg-me.com/dsproglib/6378
Last Update:
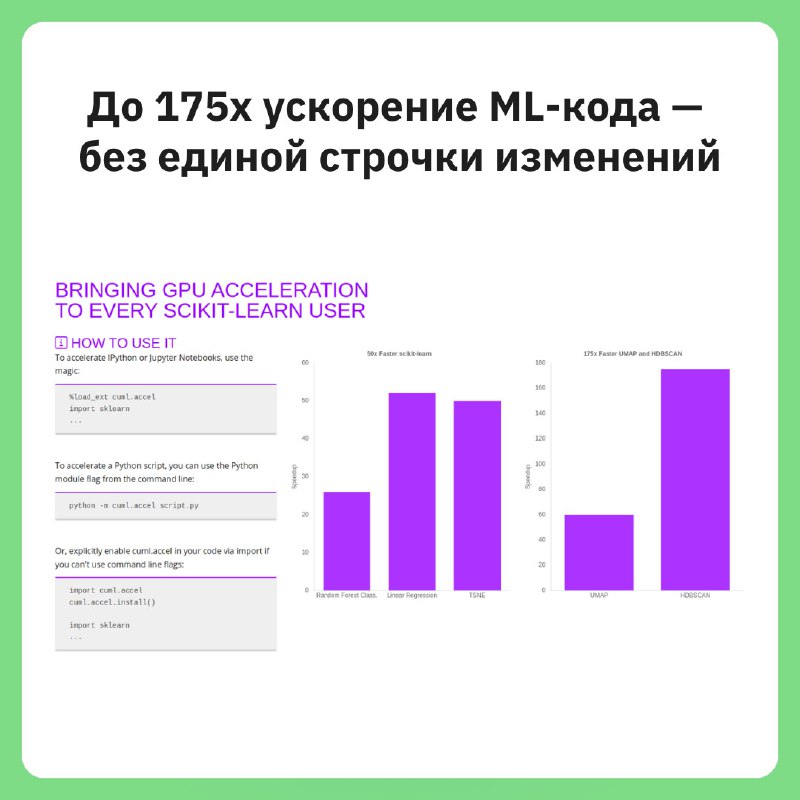
Команда cuML (NVIDIA) представила новый режим ускорения, который позволяет запускать код с scikit-learn, umap-learn и hdbscan на GPU без изменений. Просто импортируйте cuml.accel, и всё — можно работать с Jupyter, скриптами или Colab.
Это тот же «zero-code-change» подход, что и с cudf.pandas: привычные API, ускорение под капотом.
— Совместимые модели подменяются на GPU-эквиваленты автоматически
— Если что-то не поддерживается — плавный откат на CPU
— Включён CUDA Unified Memory: можно не думать о размере данных (если не очень большие)
Пример:
# train_rfc.py
#%load_ext cuml.accel # Uncomment this if you're running in a Jupyter notebook
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
# Generate a large dataset
X, y = make_classification(n_samples=500000, n_features=100, random_state=0)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# Set n_jobs=-1 to take full advantage of CPU parallelism in native scikit-learn.
# This parameter is ignored when running with cuml.accel since the code already
# runs in parallel on the GPU!
rf = RandomForestClassifier(n_estimators=100, random_state=0, n_jobs=-1)
rf.fit(X_train, y_train)
Запуск:
python train.py — на CPU python -m cuml.accel train.py — на GPU %load_ext cuml.accelПример ускорения:
🔗 Документация: https://clc.to/4VVaKg
Библиотека дата-сайентиста #свежак